Optimization of hyper-parameters¶
The model evidence cannot only be used to compare different kinds of
time series models, but also to optimize the hyper-parameters of a given
transition model by maximizing its evidence value. The Study class
of bayesloop contains a method optimize which relies on the
minimize function of the scipy.optimize module. Since
bayesloop has no gradient information about the hyper-parameters, the
optimization routine is based on the
COBYLA algorithm. The
following two sections introduce the optimization of hyper-parameters
using bayesloop and further describe how to selectively optimize
specific hyper-parameters in nested transition models.
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt # plotting
import seaborn as sns # nicer plots
sns.set_style('whitegrid') # plot styling
import numpy as np
import bayesloop as bl
# prepare study for coal mining data
S = bl.Study()
S.loadExampleData()
L = bl.om.Poisson('accident_rate', bl.oint(0, 6, 1000))
S.set(L)
+ Created new study.
+ Successfully imported example data.
+ Observation model: Poisson. Parameter(s): ['accident_rate']
Global optimization¶
The optimize method supports all currently implemented transition
models with continuous hyper-parameters, as well as combinations of
multiple models. The change-point model as well as the serial transition
model represent exceptions here, as their parameters tChange and
tBreak, respectively, are discrete. These discrete parameters are
ignored by the optimization routine. See the tutorial on change-point
studies for further information on how to
analyze structural breaks and change-points. By default, all continuous
hyper-parameters of the transition model are optimized. bayesloop
further allows to selectively optimize specific hyper-parameters, see
below. The
parameter values set by the user when defining the transition model are
used as starting values. During optimization, only the log-evidence of
the model is computed. When finished, a full fit is done to provide the
parameter distributions and mean values for the optimal model setting.
We take up the coal mining example again, and stick with the serial transition model defined here. This time, however, we optimize the slope of the linear decrease from 1885 to 1895 and the magnitude of the fluctuations afterwards (i.e. the standard deviation of the Gaussian random walk):
In [2]:
# define linear decrease transition model
def linear(t, slope=-0.2):
return slope*t
T = bl.tm.SerialTransitionModel(bl.tm.Static(),
bl.tm.BreakPoint('t_1', 1885),
bl.tm.Deterministic(linear, target='accident_rate'),
bl.tm.BreakPoint('t_2', 1895),
bl.tm.GaussianRandomWalk('sigma', 0.1, target='accident_rate'))
S.set(T)
S.optimize()
plt.figure(figsize=(8, 4))
plt.bar(S.rawTimestamps, S.rawData, align='center', facecolor='r', alpha=.5)
S.plot('accident_rate')
plt.xlim([1851, 1962])
plt.xlabel('year');
+ Transition model: Serial transition model. Hyper-Parameter(s): ['slope', 'sigma', 't_1', 't_2']
+ Starting optimization...
--> All model parameters are optimized (except change/break-points).
+ Log10-evidence: -72.93384 - Parameter values: [-0.2 0.1]
+ Log10-evidence: -96.81252 - Parameter values: [ 0.8 0.1]
+ Log10-evidence: -75.18192 - Parameter values: [-0.2 1.1]
+ Log10-evidence: -78.43877 - Parameter values: [-1.19559753 0.00626873]
+ Log10-evidence: -78.80509 - Parameter values: [-0.69779877 0.05313437]
+ Log10-evidence: -85.79404 - Parameter values: [ 0.04572939 0.05398839]
+ Log10-evidence: -72.76628 - Parameter values: [-0.21058883 0.34977565]
+ Log10-evidence: -73.72301 - Parameter values: [-0.33553394 0.34607154]
+ Log10-evidence: -74.02943 - Parameter values: [-0.08663732 0.3659319 ]
+ Log10-evidence: -73.17022 - Parameter values: [-0.14861308 0.35785378]
+ Log10-evidence: -72.79393 - Parameter values: [-0.21462789 0.38076353]
+ Log10-evidence: -72.92776 - Parameter values: [-0.27089564 0.33336413]
+ Log10-evidence: -72.76915 - Parameter values: [-0.24074224 0.34156989]
+ Log10-evidence: -72.76679 - Parameter values: [-0.20498306 0.33519087]
+ Log10-evidence: -72.78617 - Parameter values: [-0.20460701 0.35480089]
+ Log10-evidence: -72.75279 - Parameter values: [-0.21791489 0.347062 ]
+ Log10-evidence: -72.74424 - Parameter values: [-0.21953173 0.33941864]
+ Log10-evidence: -72.74031 - Parameter values: [-0.22648739 0.33586139]
+ Log10-evidence: -72.73350 - Parameter values: [-0.22642717 0.32804913]
+ Log10-evidence: -72.72784 - Parameter values: [-0.22747605 0.32030735]
+ Log10-evidence: -72.72743 - Parameter values: [-0.23183807 0.313826 ]
+ Log10-evidence: -72.72248 - Parameter values: [-0.22818709 0.31243706]
+ Log10-evidence: -72.71753 - Parameter values: [-0.22205348 0.30759827]
+ Log10-evidence: -72.72569 - Parameter values: [-0.21571672 0.31216781]
+ Log10-evidence: -72.71235 - Parameter values: [-0.22363971 0.2999485 ]
+ Log10-evidence: -72.70840 - Parameter values: [-0.22123414 0.29251557]
+ Log10-evidence: -72.70418 - Parameter values: [-0.22439552 0.28537129]
+ Log10-evidence: -72.70077 - Parameter values: [-0.22547625 0.2776339 ]
+ Log10-evidence: -72.70450 - Parameter values: [-0.23171754 0.2729348 ]
+ Log10-evidence: -72.70076 - Parameter values: [-0.21867277 0.27379362]
+ Log10-evidence: -72.69810 - Parameter values: [-0.22058074 0.27038503]
+ Log10-evidence: -72.69617 - Parameter values: [-0.2224925 0.26697858]
+ Log10-evidence: -72.69482 - Parameter values: [-0.22372428 0.26327162]
+ Log10-evidence: -72.69366 - Parameter values: [-0.22269705 0.25950286]
+ Log10-evidence: -72.69256 - Parameter values: [-0.22373849 0.255738 ]
+ Log10-evidence: -72.69157 - Parameter values: [-0.2233398 0.25185215]
+ Log10-evidence: -72.69093 - Parameter values: [-0.22465019 0.24817225]
+ Log10-evidence: -72.69026 - Parameter values: [-0.22230095 0.24505137]
+ Log10-evidence: -72.68984 - Parameter values: [-0.22155855 0.24121632]
+ Log10-evidence: -72.69200 - Parameter values: [-0.21792638 0.23977891]
+ Log10-evidence: -72.68976 - Parameter values: [-0.22524306 0.23991896]
+ Log10-evidence: -72.68944 - Parameter values: [-0.2249306 0.23799099]
+ Log10-evidence: -72.68913 - Parameter values: [-0.22449406 0.23608727]
+ Log10-evidence: -72.68891 - Parameter values: [-0.22415052 0.2341646 ]
+ Log10-evidence: -72.68891 - Parameter values: [-0.22465387 0.23227745]
+ Log10-evidence: -72.68873 - Parameter values: [-0.22367816 0.23223652]
+ Log10-evidence: -72.68886 - Parameter values: [-0.22184677 0.23155776]
+ Log10-evidence: -72.68877 - Parameter values: [-0.22341493 0.23317694]
+ Log10-evidence: -72.68870 - Parameter values: [-0.22323996 0.23202113]
+ Log10-evidence: -72.68870 - Parameter values: [-0.22291326 0.23165823]
+ Log10-evidence: -72.68875 - Parameter values: [-0.22250844 0.23193124]
+ Log10-evidence: -72.68867 - Parameter values: [-0.22322072 0.23127891]
+ Log10-evidence: -72.68866 - Parameter values: [-0.22344227 0.23084378]
+ Log10-evidence: -72.68864 - Parameter values: [-0.22319177 0.23042466]
+ Log10-evidence: -72.68863 - Parameter values: [-0.22300139 0.22997502]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22340318 0.22969756]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22359843 0.22925002]
+ Log10-evidence: -72.68864 - Parameter values: [-0.22362574 0.22979791]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22331126 0.22965818]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22321913 0.22961928]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22312139 0.22959815]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22319968 0.22966534]
+ Log10-evidence: -72.68862 - Parameter values: [-0.22319262 0.22952285]
+ Log10-evidence: -72.68861 - Parameter values: [-0.22320182 0.22942328]
+ Log10-evidence: -72.68861 - Parameter values: [-0.22319833 0.22932334]
+ Log10-evidence: -72.68861 - Parameter values: [-0.22324289 0.22923382]
+ Log10-evidence: -72.68861 - Parameter values: [-0.22322927 0.22913475]
+ Log10-evidence: -72.68861 - Parameter values: [-0.22322709 0.22903477]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22326426 0.22894194]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22322328 0.22885071]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22319605 0.22875449]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22322886 0.22866003]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22321891 0.22856053]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22322983 0.22846113]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22316925 0.22855468]
+ Log10-evidence: -72.68860 - Parameter values: [-0.22324084 0.22846296]
+ Finished optimization.
+ Started new fit:
+ Formatted data.
+ Set prior (function): jeffreys. Values have been re-normalized.
+ Finished forward pass.
+ Log10-evidence: -72.68860
+ Finished backward pass.
+ Computed mean parameter values.
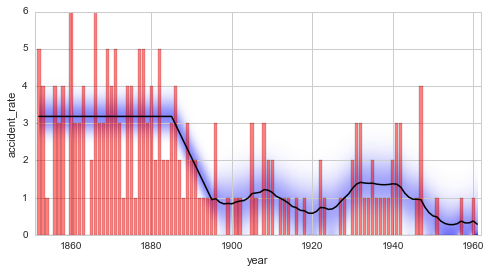
The optimal value for the standard deviation of the varying disaster rate is determined to be \(\approx 0.23\), the initial guess of \(\sigma = 0.1\) is therefore too restrictive. The value of the slope is only optimized slightly, resulting in an optimal value of \(\approx -0.22\). The optimal hyper-parameter values are displayed in the output during optimization, but can also be inspected directly:
In [3]:
print 'slope =', S.getHyperParameterValue('slope')
print 'sigma =', S.getHyperParameterValue('sigma')
slope = -0.223240841019
sigma = 0.228462963962
Conditional optimization in nested transition models¶
The previous section introduced the optimize method of the Study
class. By default, all (continuous) hyper-parameters of the chosen
transition model are optimized. In some applications, however, only
specific hyper-parameters may be subject to optimization. Therefore, a
list of parameter names (or a single name) may be passed to
optimize, specifying which parameters to optimize. Note that all
hyper-parameters have to be given a unique name. An example for a (quite
ridiculously) nested transition model is defined below. Note that the
deterministic transition models are defined via lambda functions.
In [4]:
T = bl.tm.SerialTransitionModel(bl.tm.CombinedTransitionModel(
bl.tm.GaussianRandomWalk('early_sigma', 0.05, target='accident_rate'),
bl.tm.RegimeSwitch('pmin', -7)
),
bl.tm.BreakPoint('first_break', 1885),
bl.tm.Deterministic(lambda t, slope_1=-0.2: slope_1*t, target='accident_rate'),
bl.tm.BreakPoint('second_break', 1895),
bl.tm.CombinedTransitionModel(
bl.tm.GaussianRandomWalk('late_sigma', 0.25, target='accident_rate'),
bl.tm.Deterministic(lambda t, slope_2=0.0: slope_2*t, target='accident_rate')
)
)
S.set(T)
+ Transition model: Serial transition model. Hyper-Parameter(s): ['early_sigma', 'pmin', 'slope_1', 'late_sigma', 'slope_2', 'first_break', 'second_break']
This transition model assumes a combination of gradual and abrupt changes until 1885, followed by a deterministic decrease of the annual disaster rate until 1895. Afterwards, the disaster rate is modeled by a combination of a decreasing trend and random fluctuations. Instead of discussing exactly how meaningful the proposed transition model really is, we focus on how to specify different (groups of) hyper-parameters that we might want to optimize.
All hyper-parameter names occur only once within the transition model
and may simply be stated by their name: S.optimize('pmin'). Note
that you may also pass a single or multiple hyper-parameter(s) as a
list: S.optimize(['pmin']), S.optimize(['pmin', 'slope_2']). For
deterministic models, the argument name also represents the
hyper-parameter name:
In [5]:
S.optimize(['slope_2'])
+ Starting optimization...
--> Parameter(s) to optimize: ['slope_2']
+ Log10-evidence: -72.78352 - Parameter values: [ 0.]
+ Log10-evidence: -93.84882 - Parameter values: [ 1.]
+ Log10-evidence: -80.98325 - Parameter values: [-1.]
+ Log10-evidence: -85.81409 - Parameter values: [-0.5]
+ Log10-evidence: -82.83302 - Parameter values: [ 0.25]
+ Log10-evidence: -73.27797 - Parameter values: [-0.125]
+ Log10-evidence: -74.00209 - Parameter values: [ 0.0625]
+ Log10-evidence: -72.56560 - Parameter values: [-0.03125]
+ Log10-evidence: -72.59014 - Parameter values: [-0.0625]
+ Log10-evidence: -72.54880 - Parameter values: [-0.046875]
+ Log10-evidence: -72.59014 - Parameter values: [-0.0625]
+ Log10-evidence: -72.56237 - Parameter values: [-0.0546875]
+ Log10-evidence: -72.54744 - Parameter values: [-0.04296875]
+ Log10-evidence: -72.54976 - Parameter values: [-0.0390625]
+ Log10-evidence: -72.54814 - Parameter values: [-0.04101562]
+ Log10-evidence: -72.54744 - Parameter values: [-0.04394531]
+ Log10-evidence: -72.54752 - Parameter values: [-0.04443359]
+ Log10-evidence: -72.54742 - Parameter values: [-0.04370117]
+ Log10-evidence: -72.54741 - Parameter values: [-0.04345703]
+ Log10-evidence: -72.54742 - Parameter values: [-0.04321289]
+ Log10-evidence: -72.54741 - Parameter values: [-0.04335703]
+ Log10-evidence: -72.54741 - Parameter values: [-0.04355703]
+ Finished optimization.
+ Started new fit:
+ Formatted data.
+ Set prior (function): jeffreys. Values have been re-normalized.
+ Finished forward pass.
+ Log10-evidence: -72.54741
+ Finished backward pass.
+ Computed mean parameter values.
Although the optimization of hyper-parameters helps to objectify the choice of hyper-parameter values and may even be used to gain new insights into the dynamics of systems, optimization alone does not provide any measure of uncertainty tied to the obtained, optimal hyper-parameter value. The next tutorial discusses an approach to infer not only the time-varying parameter distributions, but also the distribution of hyper-parameters.